Long ago, on the @soupgiant account, I tweeted:
Vaild html / css doesn't indicate your code is best practice; it may even indicate the opposite. #css3 ^pw
— Soup Giant (@soupgiant) April 29, 2010
While neither the xHTML nor the CSS on this site validates, we consider it to observe best practices.The HTML fails validation due to the following problems:
- One of the WordPress plugins we use on the site inserts JavaScript with unencoded ampersands in the URL. This isn’t a best practice but unfortunately it’s beyond our control;
- The
<html>tag has a class attribute; - Two of the fields in our comment form have an unrecognised value for the
typeattribute.
The CSS fails validation due to the following problems:
- We load the YUI 2.7.0 CSS reset, base and fonts files from the Google AJAX API servers. These files contain star hacks for IE targeting;
- We use browser extensions to implement CSS rounded corners and rgba backgrounds;
- Until I started writing this post, we styled a heading with
font-size: 145.4545%%.
That last one was a typo, and has since been fixed.
Justifying the invalid CSS
We’d prefer to avoid the star hacks in YUI’s CSS. If we self-hosted the files they’d be moved into the CSS files with our other IE specific hacks and targeted with conditional comments. Our compromise is to load the files from Google’s server with the aim that our site will load faster. Either the user will already have the files in their browser cache, or the user will load the files from a closer, faster server on Google’s global network.
The W3C’s CSS validator also screams at us for using CSS3 browser extensions and rgba backgrounds. While the browser manufacturers are still trying out their implementations of the new specs, we’ve no choice but to use these for the time being. As they iron out their implementations and move them over to the specified properties we can remove these. CSS3 junkies could probably have skipped this paragraph.
Justifying the invalid HTML
This site uses xHTML. We’ve discussed using HTML5 but WordPress, which powers Big Red Tin, isn’t ready to drop the /> from self closing tags. At this stage the HTML5 spec is too dynamic for our liking. Have a late afternoon snooze and the spec is likely to change during your siesta.*
Depending on your point of view, and even what you are coding, it is either fortunate or unfortunate that browsers don’t always follow specs to the letter. We’ve taken advantage of that to throw one of the biggest advantages of HTML5 into our xHTML. In our comments form, we’ve used HTML5 type attributes for two of our fields: <input type=”email” … /> and <input type=”url” … />.
In browsers that do not support these types of inputs the type falls back to the standard of type=”text”. In browsers that do support input types of email and url, it prevents the user from entering an erroneous value. For users of the iPhone or iPad, a special keyboard is presented to make entering an email address or URL easier. In browsers that support the new HTML5 input types, the behaviour is identical regardless of the doc type.
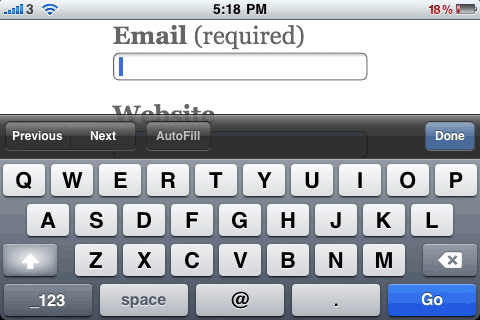
It may be breaking some of the rules of standards. To me it’s not so much about standards as best practices and giving the user the best possible experience on a site, even if this means breaking the rules sometimes.
Don’t take that to mean that we’ll be reverting to table layouts, or insert code such as <a href="#"><h1>Heading</h1></a> into our xHTML. It’s bending the rules around the edges, which is no different to using vendor prefixes to make use of CSS3.
*Yes. I know this is an unfair characterisation. A lot of very important people, with very important lawyers, are working hard to change this.